

 Processing
Processing
xGen™ for Library Normalization
With xGen Library Normalization, we’ve made library pooling easy. Normalase technology improves cluster density and library balance and has options for WGS and hybridization capture workflows—saving you critical time and effort.
xGen NGS—made to streamline.
Overview
xGen Normalization offers a novel enzymatic technology that consolidates DNA or RNA library normalization and pooling for loading on Illumina® sequencing systems. The workflow eliminates the need for library concentration adjustment prior to library pooling, improving cluster density and library balance (Figure 1).
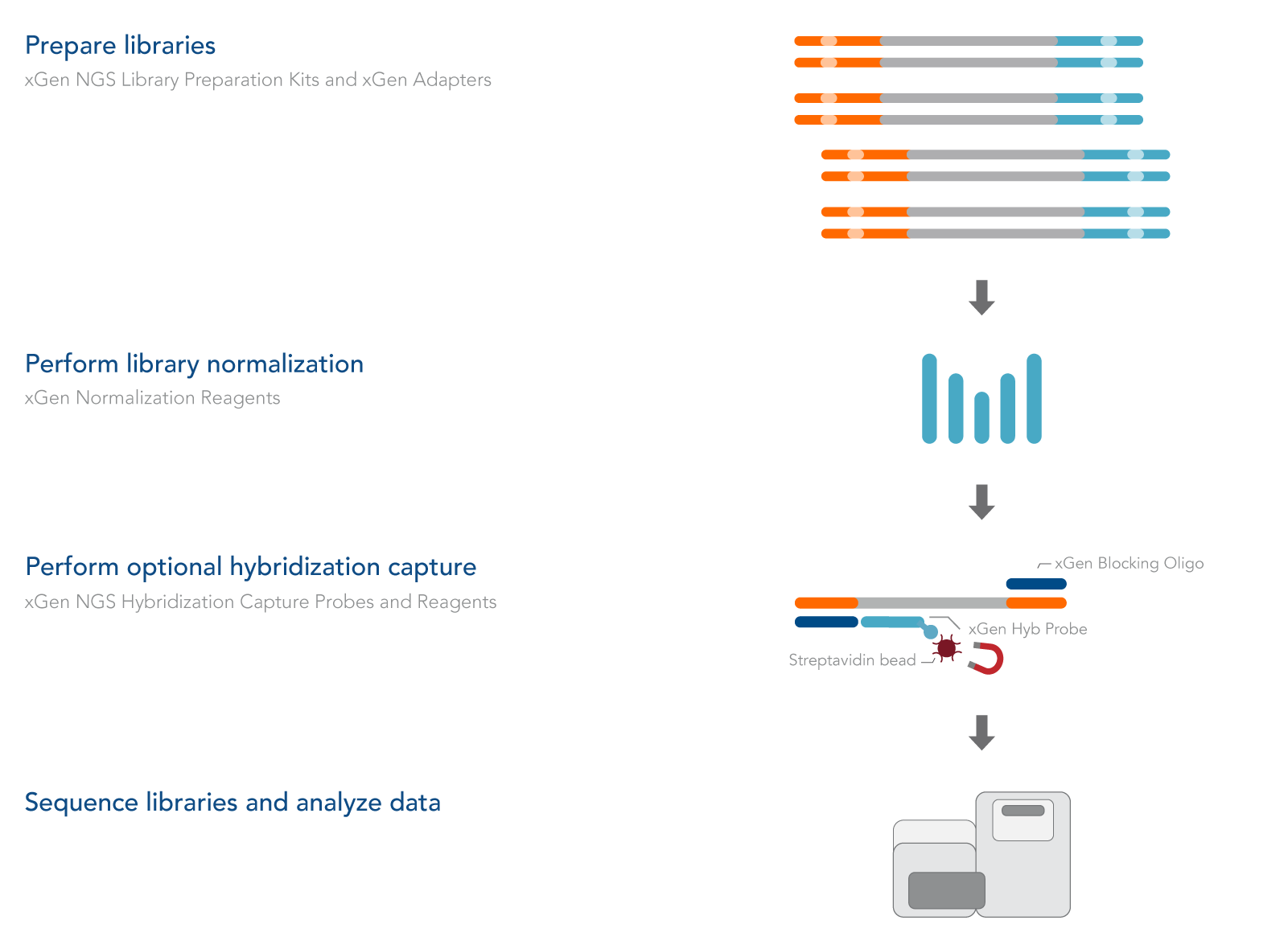
Figure 1. The xGen Normalization workflow.
The xGen Normalization method can easily be integrated into standard library preparation and hybridization capture protocols to improve turnaround time and loading accuracy for NGS laboratories (Table 1).
All xGen Normalization protocols are automation friendly. For more information, contact us.
Table 1. Key benefits of the xGen Normalase Module and xGen Pre-Hybridization Capture Normalase Module.
| Automation friendly | Saves hands-on time and resources | Integration into NGS library prep | Compatible with hybridization capture workflows | |
|---|---|---|---|---|
| xGen Normalase Module | ✔ | ✔ | ✔ | |
| xGen Pre-Hybridization Capture Normalase Module | ✔ | ✔ | ✔ | ✔ |
RUO23-2435_001